RL-driven AD
The rise of artificial intelligence (AI) have demonstrated their capabilities in developing intelligent controllers for autonomous driving (AD). Techniques like reinforcement learning (RL), with algorithms like DQN PPO, have enabled the creation of AD agents capable of learning diverse driving behaviors. These learning-based approaches offer advantages in efficiency and robustness compared to traditional rule-based methods. However, despite their potential, ensuring the safety of decision-making in these AI-driven AD systems remains a critical challenge. The inherent complexity of RL models, coupled with the stochastic nature of their learning process, makes it difficult to provide rigorous guarantees of safe operation.
One promising approach to mitigate this challenge is the concept of a safety shield. This shield acts as an intermediary layer between the AI agent’s decision-making process and the actual control of the vehicle. Its primary function is to monitor and validate the actions proposed by the AI agent to prevent dangerous situations. Typically, a set of safety rules, which can encompass different aspects of safe driving, such as maintaining safe distances from other vehicles, are defined in advance, and once the AI agent’s proposed action violates any of these safety rules, the safety shield intervenes, either by modifying the action to a safe alternative or by preventing its execution altogether.
Decision-making Safety Shield based on Online model checking
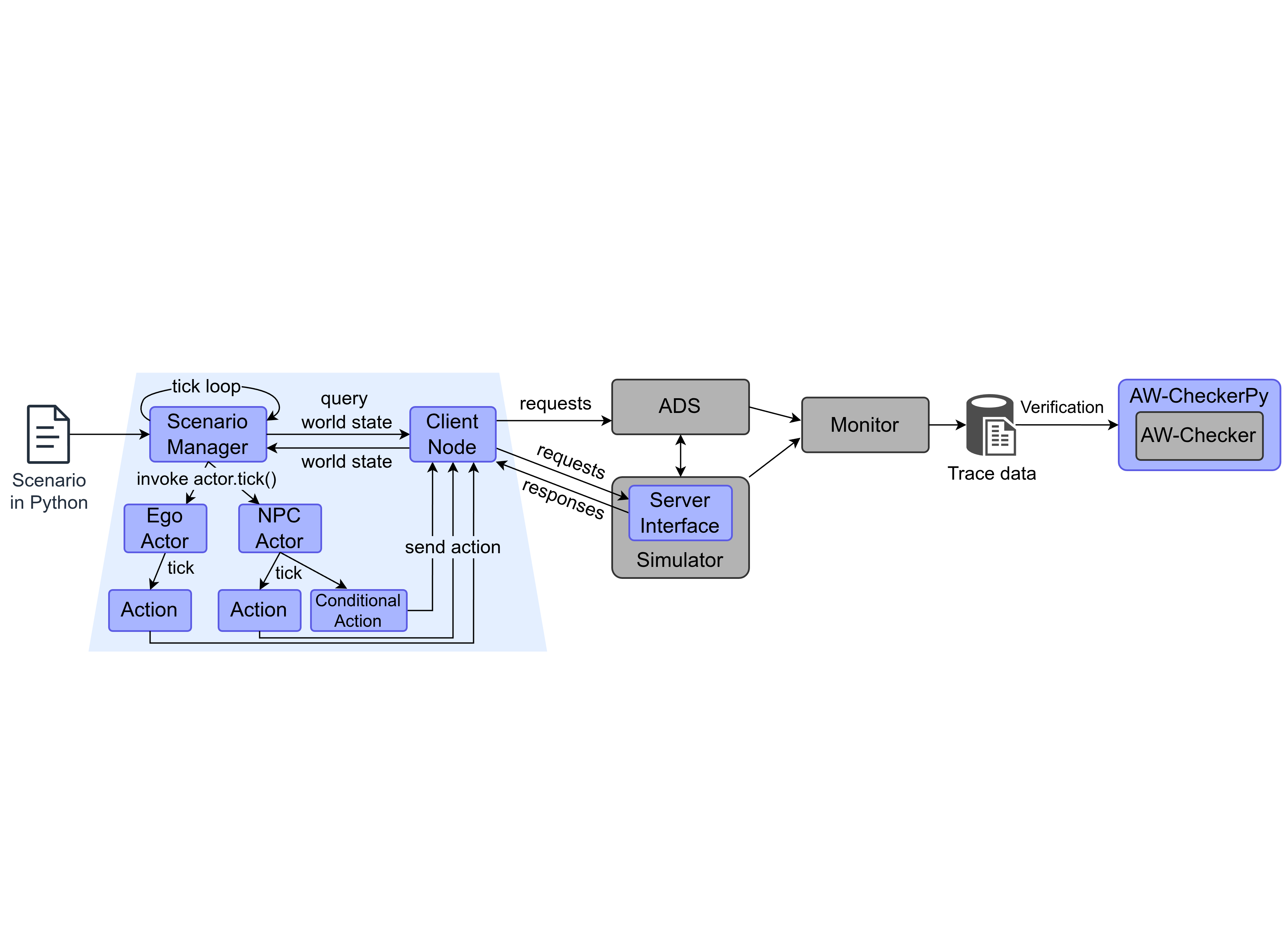
In this work, we propose leveraging online model checking to develop a safety shield for AD. Online model checking is a lightweight runtime verification technique designed to ensure the correctness of a system’s execution trace as it runs. Unlike traditional model checking, which exhaustively explores the entire state space, online model checking operates incrementally by analyzing only a partial model space corresponding to the system’s current execution. Thus, it mitigates the state space explosion problem that often hinders the application of model checking to complex systems. This characteristic makes online model checking particularly well-suited for developing a safety shield in AI-driven AD. At each verification cycle, by synchronizing the current state of the formal model with the driving environment, irrelevant states can be eliminated from the search state space. Furthermore, since it suffices to ensure safety only until the next verification cycle, we can limit the search depth, ensuring that the model-checking process always succeeds within a short amount of time. To the best of our knowledge, this work represents the first application of online model checking to safety verification in the AD domain.
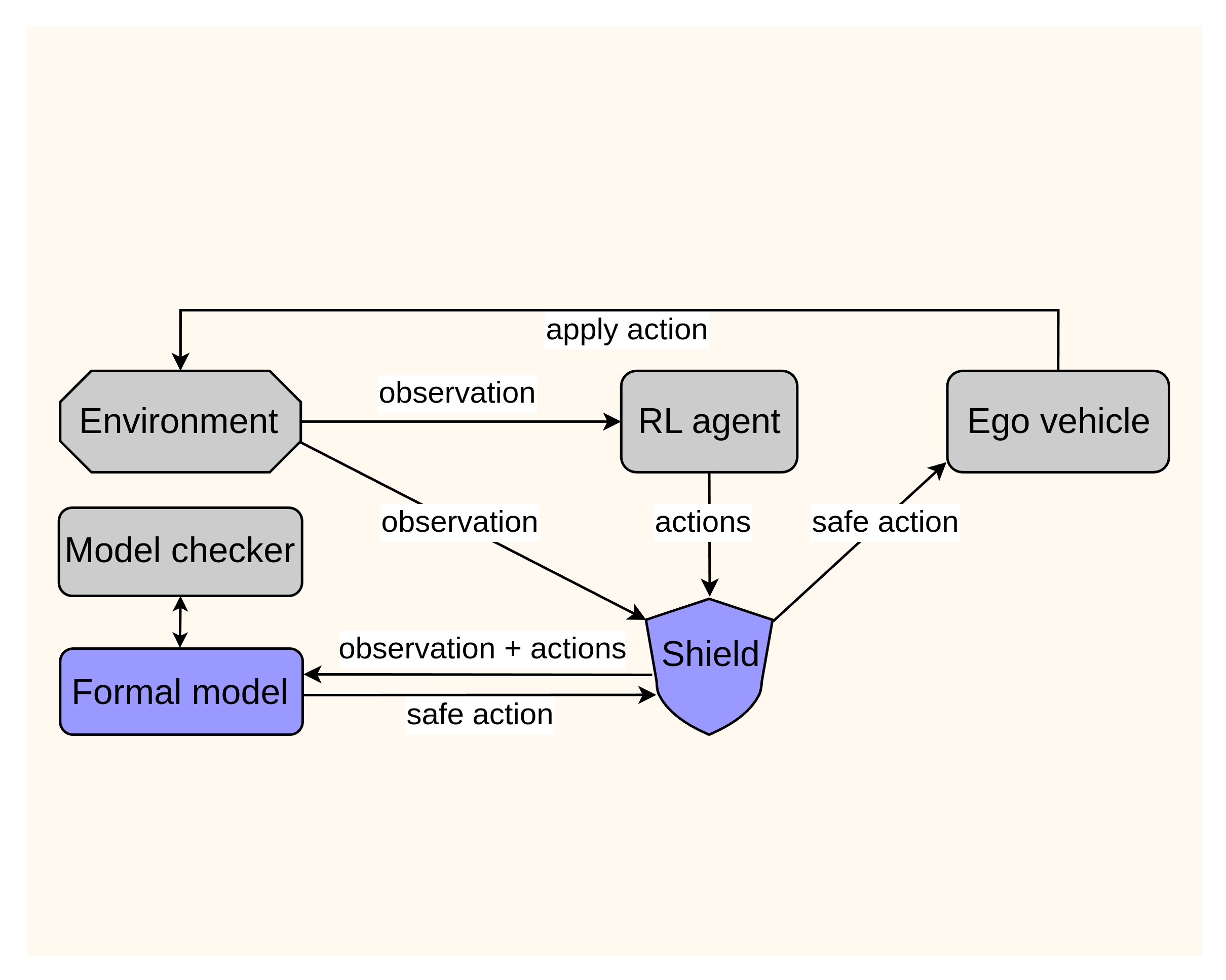
We demonstrate our approach through a highway AD case study, which is the challenge proposed for the ABZ 2025 conference. A safety shield is developed and evaluated with several RL agents. In essence, the safety shield intervenes before executing the RL agent’s chosen action. Instead of blindly applying the top-ranked action, our shield validates and selects the safest option from a ranked list of candidate actions proposed by the RL agent. To achieve this, a formal model is maintained, specifying the environment’s state, including the status of the ego and NPC vehicles, as well as vehicle kinematics that govern their motion (e.g., speeding up and slowing down). Safety requirements for AD can be expressed as invariant properties w.r.t. this model. Specifically, at each cycle, our method follows these steps:
-
The RL agent generates a ranked list of candidate actions, sorted from high to low (ordinarily, the first action in this list would be executed directly), passing to the shield.
-
The shield updates the encoded system state within the formal model based on the current observation and the RL agent’s proposed actions.
-
For each candidate action (starting from the highest-ranked one), we per- form online model checking against the negation of the invariant property specifying the safety concerned. If a counterexample is found, it indicates that executing this action may lead to an unsafe state (w.r.t. the encoded safety requirements).
-
The shield iterates through the ranked list until it finds an action with no counterexample—this action is then passed to the ego vehicle as the safe action for execution.
Safety requirements
In the context of AD, safety requirements must go beyond simply avoiding collisions. A common approach to enhancing safety is to enforce the ego vehicle to maintain a safe distance from surrounding vehicles. This can be quantified using metrics such as Time-To-Collision (TTC) and mod- els like Responsibility-Sensitive Safety.
In this work, we define the safety requirements for AD based on TTC as follows:
SR: The TTC with any other vehicle must never be lower than 2 seconds.
The two-second threshold aligns with the Japanese safety standard, and the United Nations Regulation (UNR) collision warning guidelines, which define the boundary for emergency action at a TTC of two seconds. This guideline establishes a standardized risk evaluation boundary for maintaining safe distances from other vehicles. By adopting this criterion, we ensure that the ego vehicle has sufficient reaction time to avoid hazardous situations in dynamic driving environments.
Experimental results
We conducted a series of experiments in the simulated environment Highway-env with two different road configurations: a single-lane highway and a three-lane highway. Experimental results demonstrate that the safety shield effectively prevents collisions and improves adherence to safety constraints. By validating actions before execution, the safety shield ensures that decision-making remains within predefined safety requirements. While minor trade-offs in driving efficiency were observed, their impact was minimal, and the shield successfully balanced safety and maneuverability, as evidenced by the travel distance as well as right lane change and speeding up approval rates.
The formal model, shield implementation, RL agents, experiment traces, and other supporting materials are available at https://github.com/fomaad/ OnlineMC-SafetyShield.
Publications
Enhancing Decision-making Safety in Autonomous Driving Through Online Model Checking. Duong Dinh Tran, Akira Hasegawa, Peter Riviere, Takashi Tomita, and Toshiaki Aoki. In 11th International Conference on Rigorous State Based Methods, ABZ 2025, 2025.